

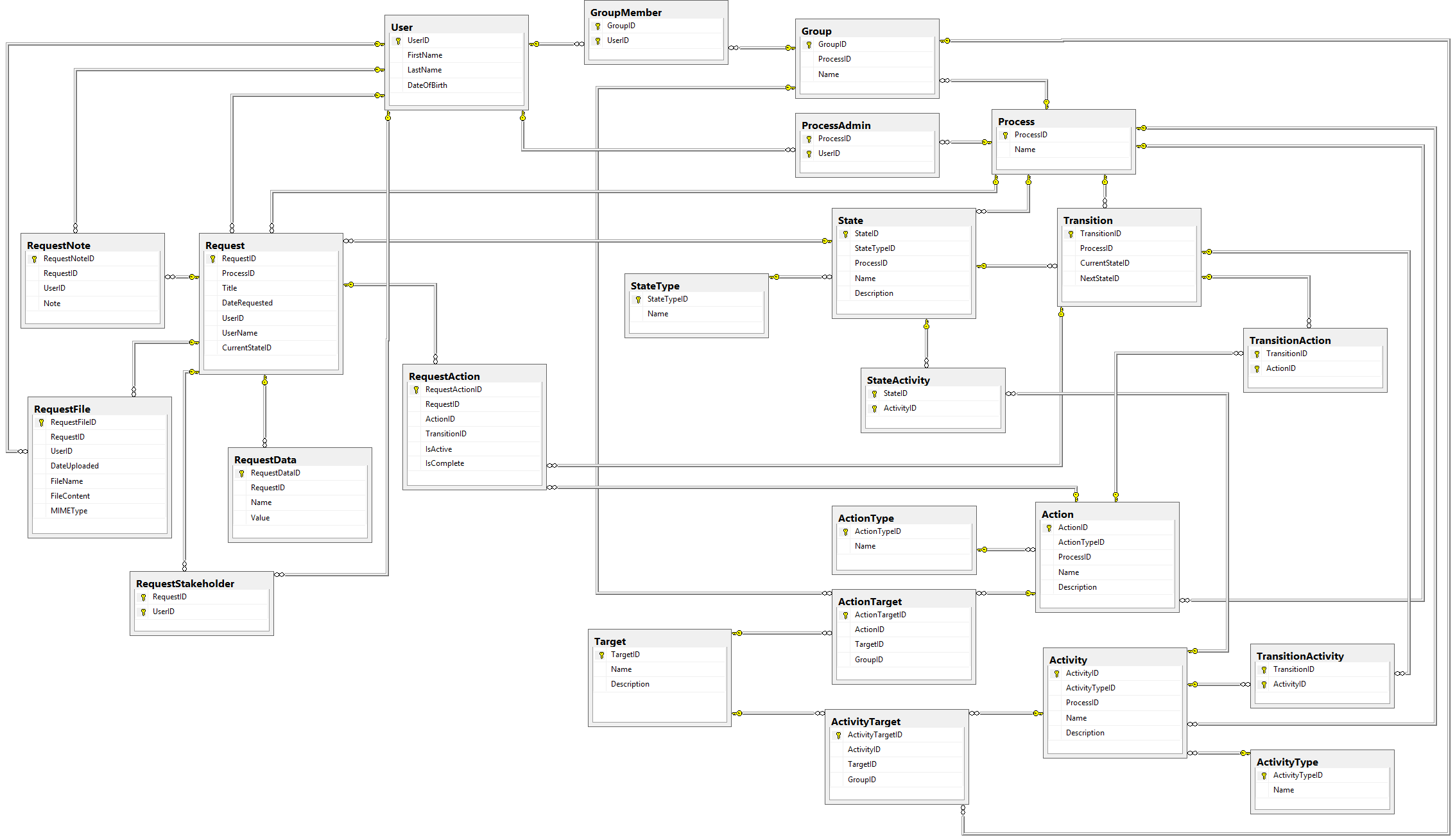
One of the first steps in creating any database table is deciding what kind of data will uniquely identify a given row in said table; we call this a primary key. In modern databases, if we want to create a unique key from "thin air" and not use already-existing data (this situation is known as using a surrogate key) we have two commonly-accepted options: using integers, or using Globally-Unique Identifiers (GUIDs).
Both integers and GUIDs can be generated automatically, either by the database itself or some other system. But which is better? Let's discuss the pros and cons of using integers and GUIDs as primary keys, and see if we can discover which works better for our databases and applications.

Roman keys by MatthiasKabel, used under license
Using Integers
The primary argument in favor of using integers for primary keys is due to their simplicity. After all, they're just numbers. If you printed out a table that used integers as primary keys, the data is easy to read and understand:
| ID | Name |
|---|---|
| 1 | John |
| 2 | Kelly |
| 3 | Luis |
If we're using integers as your primary key type, it becomes easy for the user to guess what the ID of a certain thing is (which may or may not be what you want). Let's imagine that a user encounters a URL similar to this one
/locations/5/hours
If the user already knew that the ID of the location s/he wants to see is 120, all they have to do is change the URL like so:
/locations/120/hours
In this way, the user can gain some extra knowledge about the system and start becoming able to make predictions as to what information exists where. Overall, it makes the user experience of our applications nicer.
Finally, integers are tiny; they use only 4 bytes of storage. This means that things like indexing and querying, in general, will be quicker when using integers as your primary key type. However, you probably won't see any difference until/unless you've got a massive application in place.
In short, use Integers when:
- You want easily-understood IDs.
- You want your URLs to be "hackable" by your end-users.
- You are concerned about performance (in very large applications).
Using GUIDs
GUID stands for Globally-Unique Identifier, and is comprised of 32 hexadecimal characters in a format that looks like this:
65ac3d1d-f339-7aae-881a-acc6832ffe81
A GUID is a specific form of the Universally-Unique Identifier idea, which was formally laid out by the Internet Engineering Task Force (IETF) as RFC 4122. The term GUID and its format were originally developed and used by Microsoft.
The defining characteristic of a GUID is that it is, comparatively speaking, huge; it uses 16 bytes of storage, versus only 4 bytes for an integer. But why would anybody need such large entropy in a data type? Let's do some math to discover that answer.
A GUID contains 2128 possible combinations, which means 3.4x1038 possible unique values can be generated from this structure. When written out, this number looks approximately like this:
34,028,236,692,093,846,346,337,460,743,177,000,000
That is an astoundingly massive number. To put this in perspective, according to this blog there are somewhere around 5.6X1021 grains of sand on Earth's beaches. Every single one could use 6.07x1016 GUIDs without any repeats. Unless you have data sets that are impossibly large, you will never see duplicate GUIDs.
Because we are virtually guaranteed to not ever get the same GUID twice, collecting data from many disparate sources becomes much easier. If you are merging data from a database that uses GUIDs as primary keys into your database, you are so unlikely to encounter collisions that you probably won't even need to check for them. The entropy invoked by GUIDs allows us developers to not have to consider handling collisions in the vast majority of circumstances.
However, because GUIDs are so big, performance can theoretically suffer with sufficiently large data sets. Indexing, in particular, can suffer due to the size of the data being stored. Opinions vary on just how much of a performance hit you'll take, though.
Another con to using GUIDs is that they are not easily remembered by users, so you won't get the "hackable" URLs that you would when using Integers. Depending on your system, this may be acceptable.
In short, use GUIDs when:
- You want the data to be uniquely-identified, no matter where it came from.
- You need to be able to combine data from difference sources with little-to-no chance of duplicate GUIDs.
- You don't want or don't care about the users needing to remember an ID themselves.
Which Is Better?
As always, this kind of decision comes down to what kind of system you are building. But IMO you should only favor GUIDs over integers if you have a very large, distributed system where you are likely to need global uniqueness.
The performance argument against GUIDs has largely been nullified by the passage of time and improvements in technology. In modern systems you will not see any discernable performance difference between the two data types.
Further, the "hackable" argument in favor of using integers is entirely wrong-headed; why should the user have to remember anything? It's nice for the users to be able to do this, but not necessary or vital by a long shot.
Despite both of those points, I don't see a reason to invoke the extra complexity necessitated by GUIDs unless you have a correspondingly complex system. In my mind, the argument boils down to clarity vs guaranteed uniqueness, and given that the best code is no code I'll take the simplicity of integers every day of the week.
But that's just my opinion. I've laid out the best arguments I've found for using both integers and GUIDs as primary keys so that you (my readers) can go make this decision for yourself. Let me know what you decide, and why, in the comments!
Happy Coding!







{kind=link}