

A few weeks back I wrote about a very unusual bug that returned 500 errors for routes that should have been valid. Recently my team and I, to our great relief, discovered the cause of this bug. Of course, that wasn't before we ended up yelling "WTF?!" a great many times.

A great many times.
A New Failing Route
Most of the our collective WTFs occurred when we discovered the original problem. As I wrote about in the earlier post, we have an ASP.NET Web API application in which the routes /auth and /photos had been returning 500 errors whenever we tried to hit them. The odd thing was, the 500 errors always got returned immediately, even when there should have been a compilation delay. (Go read the whole post if you want the complete backstory).
We implemented a temporary fix by changing the routes for /auth and /photos to /authentication and /pictures, but that obviously is not a good long-term solution for something that should never have happened in the first place. (Not that I have a great track record with things that should have never happened in the first place, but hey, I'm an optimist.)
And then my coworker Diya noticed something that stunned us: now a new route was failing. The route /phones was also giving us the dreaded no-compilation-delay 500 errors.
Diya spent a day proving that /phones had the same issue that the other routes did, just like Nate and I had done a few weeks ago. And, sure enough, she came to the same conclusion: the route never responded for any request made to it.
But this didn't make sense to me. How could a route, which had been previously working, suddenly starting returning 500 errors? WTF?
Determining the Root Cause
I'd had just about enough of this. If our API's routes were going to randomly start failing for no damn reason, I needed to know why. I pestered our server team (which, admittedly, usually has bigger fish to fry than tracking down some fiddly route problem on a dev server) until they took a look at the server which hosted our API.
When they did finally peruse through the server, the told me that several other web applications existed there. They also sent me this screenshot:
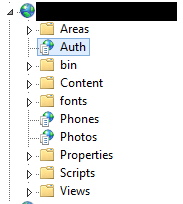
In case this wasn't clear enough, let me make the exact problem a bit more obvious:
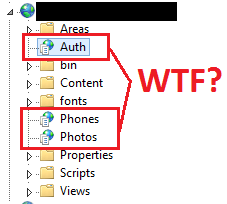
The server which hosted our API had empty web apps on it that corresponded exactly to the failing routes! So, whenever we tried to hit /auth or /phones or /photos, IIS would redirect that request to the corresponding app, and because that app wouldn't actually work, we'd get back 500 errors.
Hooray! We'd found the bug, and now we could finally kill it! Except...
Here's where the real fun begins. From our perspective, the route /phones (the route that Diya was working on) started failing after /auth and /photos (the routes that Nate and I discovered didn't work a few weeks ago). That, to me, suggests that the Phones application was created at a later time. But the server team swears up and down that all three apps were created at the same time.
How Did This Happen?
So now there are three possibilities. Either:
- The Phones web app was in fact created later, even though there's no record of that happening OR
- Something in our Continuous Integration/Continuous Deployment process is automatically creating these apps (which is extraordinarily unlikely) OR
- We never ran any code against the /phones route in the three weeks of testing we've been doing (or, if we did, didn't notice that it failed).
Occam's Razor suggests that the answer is (3). I personally don't see how that's possible with the amount of testing we've been doing over the last several weeks, but (1) and (2) are so much more unlikely that it's almost ludicrous to decide that either was the culprit. Logic suggests that we simply didn't test the /phones route, and in other news, I now hate logic.
Summary
We finally figured out why our routes were failing: there were empty applications on the server that matched the route names. Since those applications have been removed, we've been able to reset the routes to the names we wanted in the first place (/auth, /photos, and /phones). But now we're left with a worrying possibility: was an entire route (/phones) failing for three weeks and we didn't notice?
But, hey, at least it is fixed. That's good, I think. Right?
Happy Coding!









