

A while back I wrote a series of posts in which I built a simple web application that uses the Command-Query Responsibility Segregation and Event Sourcing patterns, as well as ASP.NET. I did this mostly as a way to explore these two difficult patterns, but partially as a kind of proving ground for a real-world application we were about to start working on that was going to use CQRS/ES. It worked surprisingly well for that purpose, but it also revealed a problem: the original series didn't even approach the complexity of a real-world CQRS/ES system.
CQRS contains two models: a Write Model, and a Read Model. My original series did a fairly good job of covering the Write Model, but barely touched the Read Model, which is arguably the more difficult of the two. The original justification for not fully implementing the read model was that it made the entire series too difficult, too wordy, too messy. But now, with the benefit of hindsight, I realize that you have to get messy to learn.
So that's what we're going to do in this series: get a little messy to learn about CQRS/ES in the real world.

Hopefully the clean up won't be too bad.
What is CQRS?
Before we can start implementing these patterns, we first need to answer two simple questions: what is CQRS, and what is Event Sourcing?
NOTE: I wrote an earlier post called Pattern Overview: Command-Query Responsibility Segregation and Event Sourcing which is a more in-depth introduction to these two patterns; you may want to read that if you've never used CQRS/ES before
CQRS (as mentioned above, this is short for Command-Query Responsibility Segregation) is a pattern that states one simple thing which has huge consequences for the design of your systems. CQRS states that commands and queries are completely separate things, and are executed against different models of the same data (called the Write Model and the Read Model). In many apps, the architecture might look something like this:
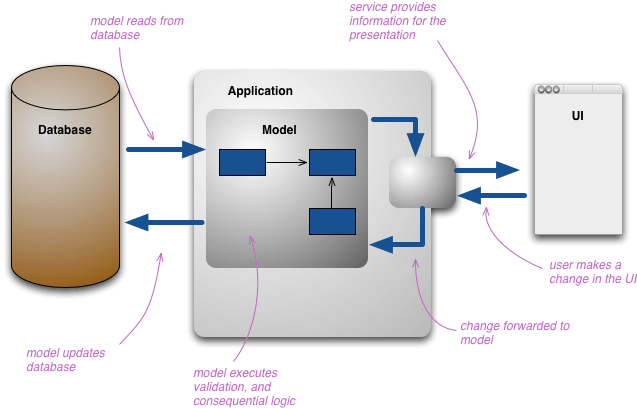
Source: Martin Fowler's Website
But in CQRS apps, the architecture looks like this:
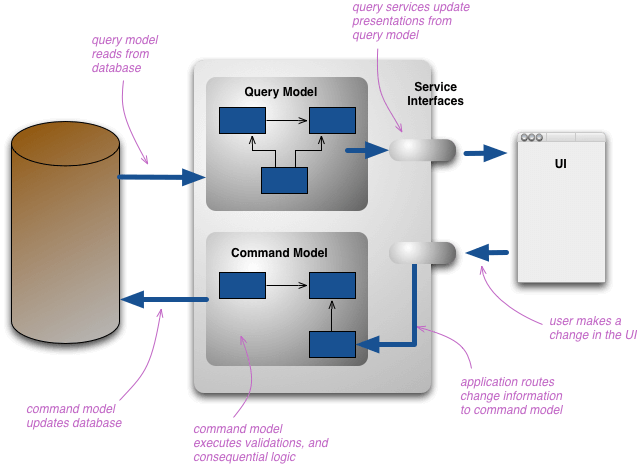
Source: Martin Fowler's Website
The reason we separate the models is so that we can model the data separately and optimally for both sides of the equation. While this is more architecture than normal CRUD applications, it allows for changes must more readily.
In short: applications which use CQRS are more difficult to setup up initially, but subsequent changes are always the same amount of work, whereas in CRUD applications subsequent changes generally take more work.
What is Event Sourcing?
Event Sourcing (ES) is an orthogonal pattern to CQRS, but they fit so well together that they often come as a pair. In a "normal" database, you store the modeled data as it exists at the moment, with all of its values and relations, etc. In an Event Sourcing data store, you store the changes to the data, not the data itself, in a form called events. These events can be re-run later at a given time to re-create the current state of the data.
What this means is that you have the entire data store at any point in time, and can re-create it at any time. But, since ES doesn't store the current state of the data, we must re-run events to get the current state before making changes to it (e.g. adding new events).
CQRS and ES are BFFs!
CQRS and ES work so well together that often you'll see CQRS/ES systems labeled as just "CQRS". The reason they fit so well is because Event Sourcing can become CQRS's Write Model, while the design of the Read Model is irrelevant to ES. So, Event Sourcing takes care of (slightly-less-than) half of the CQRS equation. In the diagram below, Event Sourcing is way of modeling the Update data store.
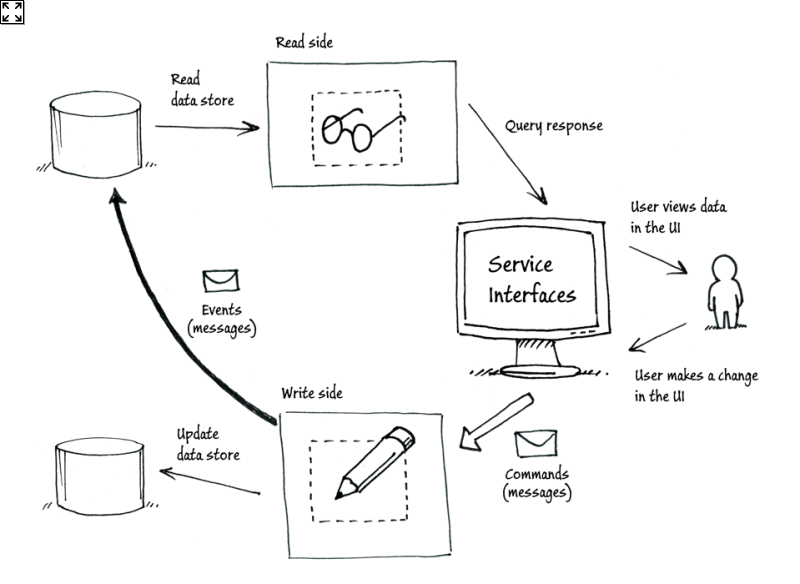
Source: Introducing Event Sourcing from MSDN
The problem (and there's always a problem) is that CQRS/ES is difficult to set up. It's a lot of moving pieces, and the way those pieces fit together is not at all obvious. While CQRS/ES is, to be frank, a pain in the ass at the beginning, it carries some significant benefits:
- You can restore the data (specifically the Read Model) to whatever point in time you wish by re-running the necessary Events.
- Because the Events are stored as serialized JSON, re-running them is (generally) blazing fast, so the performance of the system tends to be pretty darn good.
- Any subsequent changes do not get more difficult to implement; at worst they are the same amount of work as any other change.
Why Use CQRS/ES?
This is ultimately the question you need to answer when deciding whether or not to use CQRS/ES in your application. Use CQRS/ES if:
- Performance is critical to this app,
- You need a way to see all the data at any point in time,
- You're willing to suffer the extra architecture you'll need to put in place AND
- You can explain what this is doing to your peers (CQRS/ES is not terribly well-known IMO).
If you can do all of that, there's no reason why CQRS/ES wouldn't work for your systems!
Structure of Our Application
I said at the beginning of this post that the goal is to create a "real-world" CQRS/ES application. I'm an ASP.NET developer, so we'll be using ASP.NET Web API for both our Commands and Queries web interfaces. In addition, we'll be using the following technologies and NuGet packages:
- CQRSLite: A truly incredible CQRS package that forms the backbone of our system.
- AutoMapper: A wonderful convention-based mapped that I've used extensively in the past.
- JSON.NET: An extremely fast JSON serializer.
- StructureMap: My preferred Dependency Injection (DI) container, which I've written about before.
- FluentValidation: an extensible validation library which will assist us in validating requests which come in to our system.
- Redis: An in-memory data structure store that will store the Read Model for this application.
- StackExchange.Redis: A general-purpose Redis client designed for large, performance-critical systems.
Why Redis?
Of all of those packages, the Redis ones were the only ones I wasn't familiar with, so let's give a quick breakdown of what Redis is and where we are going to use it.
Redis in an in-memory data structure store, which means that all of its data is stored in memory rather than on the harddisk. Consequently it is stupidly fast for queries, and this is why we're using it to store our Read Model. It is also a NoSql datastore, and makes a huge distinction between keys (which are used to look up items) and everything else. We'll go into more detail of how we're going to use Redis in Part 3 of this series, but for now, know that Redis provides our Read Model data store.
Summary
Command-Query Responsibility Segregation (CQRS) and Event Sourcing (ES) are two complex patterns that fit very well together. In this series, we're going to build a CQRS/ES system from scratch and see if we can make something that approaches real-world complexity. Here's the remaining parts for this series:
- Part 2 - The Write Model: We will build the Write Model of the system, including Commands, Command Handlers, Aggregate Roots, and Events.
- Part 3 - The Read Model: We will build the Read Model, including the Redis store, the Event Handlers, and Repositories which allow us to query Read Model data.
- Part 4 - Creating the APIs: We will build both the Commands and Queries APIs using ASP.NET Web API and the NuGet packages listed above.
- Part 5 - Running the APIs: We'll run several commands and queries using Postman to see if we built our system correctly.
This series is possibly the most intricate and interesting tech stack I've blogged about, and that's what makes it so rewarding to finally be able to share it with you all. In Part 2 of this series, we'll get starting getting messy building our CQRS/ES application by designing the Write Model.
Happy Coding!









